原文:What every programmer should know about memory, Part 3: Virtual Memory
4 Virtual Memory
虚拟内存(virtual memory)是处理器的一个子系统,它给每个进程提供虚拟地址空间(virtual address space)。这让每个进程以为自己在系统中是独自一人。
虚拟内存的作用在于为进程提供“看上去”连续的地址空间,这么做的好处在于程序不需要处理内存碎片的问题了。
虚拟地址空间由CPU的Memory Management Unit(MMU)实现,操作系统必须填写页表数据结构(page table data structures,见wiki词条),大多数CPU自己完成余下的工作。
把虚拟地址(virtual address)作为输入交给MMU做翻译。在32位系统中虚拟地址是32位的,在64位系统中是64位的。
4.1 Simplest Address Translation
MMU可以逐页(page)的将虚拟地址翻译成物理地址的,和cache line一样,虚拟地址被分割成多个部分,这些部分则被索引到不同的表(table)里,这些表用来构造最终的物理地址。最简单的模型则只拥有一个级别的表(only one level of tables)。
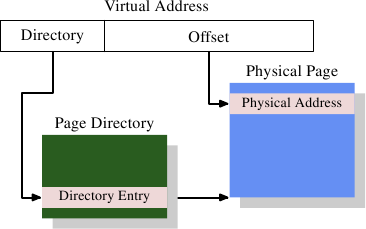
Figure 4.1: 1-Level Address Translation
虚拟地址的结构:
- 虚拟地址的头部被用来在一个页目录(Page Directory)中选择条目(entry),
- 页目录中存储的是条目(entry),每个条目可由操作系统单独设置。
- 条目决定了物理内存页的地址,即页的物理地址
- 虚拟地址的尾部是页内的偏移量
- 所以页的物理地址+偏移量=物理地址
- 页目录的条目还包含一些辅助信息,比如访问权限
页目录的存储:
- 页目录是存在内存里的,
- 操纵系统为其分配一段连续的物理内存空间,并将基地址(base address)存在一个特殊的寄存器里
- 而条目在目录里就是一个数组(记住这是数组,这对于理解下面多级目录,多级索引很重要)
先弄个速算表,下面会用得着:
- 29=512
- 210=512 * 2=1024=1K
- 220=1024 * 1024=1MB
拿x86系统,4MB页举例:
- 虚拟地址的偏移量部分占用22位(可以覆盖4MB的空间)
- 目录部分则还剩10位,即可以存放1024个条目
- 每个条目存了10位的物理页内存的基地址
- 10位+22位=32位,形成了完整的物理内存地址
4.2 Multi-Level Page Tables
多级页表(page table),注意原文写到这里用页表(page table)而不是页目录(page directory),这两个实际上是一个东西。
上面的例子拿4MB页来举例的,不过4MB页表不常见,这是因为操作系统执行的很多操作是按照页来对齐的,意思是每个页的基地址之间都差4MB的倍数,就算你要用1k内存也要申请了一个4MB的页,这造成了大量的浪费。
真实世界里32位机器大多用4kB页,同样多见于64位机器。
为啥4kB页,单级页表不行:
- 虚拟地址偏移量占12位
- 虚拟地址页目录部分占20位(64位机器就是52位)
- 页表条目数=220,就算每个条目只占4 bytes(32位)那整个页表页要占4MB
- 然后每个进程会拥有自己的页表,那么大量的物理内存就会被用在页表上。
- 实际上不光是物理内存用量太大的问题,因页表就是一个数组,需要连续的内存空间,到时候很难分配。
解决办法是使用多级页表。它们能够代表一个稀疏的巨大的页表,可以做到对没有被使用的区域(原文没有讲区域是啥)不需要分配内存。这种形式跟为紧凑,可以为许多进程提供页表,同时又不对性能产生太大影响。
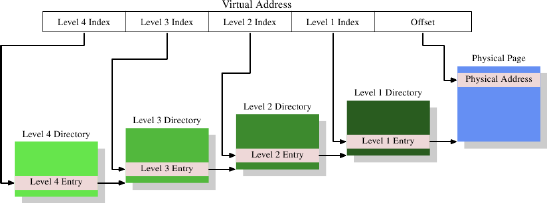
Figure 4.2: 4-Level Address Translation
上面是一个4级页表:
- 虚拟地址被分割成5个部分,其中4个部分是不同页表的索引
- 第4级页表通过CPU里的一个特殊目的的register来引用
- 第4级-第2级的页表的内容是对下一级页表引用(我觉得应该就是物理内存地址,因为前面讲过页表存在物理内存中的)
- 第1级页表存储的物理地址的一部分(应该就是去掉偏移量的那一部分)和辅助数据,比如访问权限
- 所以整个形成了一个页表树(page table tree),稀疏又紧凑(sparse and compact)
得到物理地址的步骤,Page tree walking:
- 先从register中得到第4级页表的地址,
- 拿到第4级页表
- 拿虚拟地址中Level 4 Index取得页表中的条目,这个条目里存的是第3级页表的地址
- 拿到第3级页表
- 拿虚拟地址中Level 3 Index取得页表中的条目,这个条目里存的是第2级页表的地址
- 如此反复直到拿到第1级页表里的条目,这个条目里存的是物理地址的高位部分
- 结合虚拟地址中的偏移量,得到最终的物理地址
- Page tree walking在x86、x86-64处理器里是发生在硬件层面的
Page table tree尺寸对性能的影响:
- 每个进程可能需要自己的page table tree,几个进程共享树的一部分是存在的,但这只是特例。
- 如果页表树所需内存越小,那就越有利于性能和扩展性(performance and scalability)
- 理想情况下,把使用的内存在虚拟地址空间里紧密的放在一起,就能够让page table tree占用的空间小(单独看这句没有办法明白,结合后面的内容看
- 举例,4kB/页,512条目/页表,1页表/每级,那么可以寻址2MB连续的地址空间(512*4kB=2MB)
- 举例,4kB/页,512条目/页表,4-2级只有1个页表,1级有512个页表,那么可以寻址1GB连续的地址空间(512 * 512 * 4KB=1G)
Page table tree布局:
- 假设所有内存都能够连续的被分配太过简单了
- 比如,出于灵活性的考虑(flexibility),stack和heap分占地址空间的两端,所以极有可能有2个2级页表,每个二级页表有一个1级页表。
- 显示中比上面这个更复杂,处于安全性考虑,不同的可执行部分(code、data、heap、stack、DSOs又称共享库)是被影射到随机地址上的。所以进程所使用的不同内存区域是遍布整个虚拟地址空间的。所以一个进程不可能只有一两个2级3级页表的。
个人总结,前面讲的对于多少连续的寻址空间,各级别页表需要多少个是这么计算的:
- 首先得知道前提,对于4-2级页表,在同一页表内,不同页表条目不会指向同一个下一级页表
- 对于1级页表,不同页表条目不会指向相同的物理地址(准确的说是物理地址去掉offset的部分)
- 对于4-2级页表,每个页表条目指向一个下级页表,即上级页表条目数目=下级页表数
- 假设现在是32位系统,每个页表至多保存29=512个页表项
下面举连续的2MB寻址空间(页大小为4kB):
- 2MB=210 * 210 * 2=221 bytes
- 所以需要:2MB / 4kB = 221 / 212 = 29个1级页表条目
- 所以需要:29 / 29=1个一级页表=1个2级页表条目
- 所以前面说,4kB/页,512条目/页表,1页表/每级,那么可以寻址2MB连续的地址空间
下面举例连续的1GB寻址空间(页大小为4kB):
- 1GB=210 * 210 * 210=230 bytes
- 所以需要1级页表条目:1GB / 4kB = 230 / 212=218个1级页表条目
- 所以需要:218 / 29=29个1级页表=29个2级页表条目
- 所以需要:29 / 29=1个2级页表
- 所以前面说,4kB/页,512条目/页表,4-2级只有1个页表,1级有512个页表,那么可以寻址1GB连续的地址空间(512 * 512 * 4KB=1G)
同理如果是连续的2GB寻址空间(页大小为4kB):
- 1GB=210 * 210 * 210 * 2=231 bytes
- 所以需要:1GB / 4kB = 231 / 212=219个1级页表条目
- 所以需要:219 / 29=210个1级页表=210个2级页表条目
- 所以需要:210 / 29=2个二级页表=2个3级页表条目
4.3 Optimizing Page Table Access
- 所有页表是存在main memory中的,操作系统负责构建和更新页表
- 创建进程或更新页表时CPU会收到通知
- 页表被用来每一次解析虚拟地址到物理地址的工作,采用的方式是page tree walking
- 当解析虚拟地址的时候,每级都至少有一个页表在page tree walking中被使用
- 所以每次解析虚拟地址要访问4次内存,这很慢
TLB:
- 现代CPU将虚拟地址的计算结果保存在一个叫做TLB(Tranlsation Look-Aside Buffer)的cache中。
- TLB是一个很小的cache,而且速度极快
- 现代CPU提供多级TLB,级别越高尺寸越大同时越慢。也分为数据和指令两种,ITLB和DTLB。高层级TLB比如2LTLB通常是统一的。(和前一篇文章讲的cache结构类似)
- 因为虚拟地址的offset不参与page tree walking,所以使用其余部分作为cache的tag
- 通过软件或硬件prefetch code/data会隐式的prefetch TLB条目,如果地址是在另一个page上时
4.3.1 Caveats Of Using A TLB
讲了几种优化TLB cache flush的手段,不过没有讲现代CPU使用的是哪一种。
个人认为这段不用太仔细读,只需要知道存在一种手段可以最少范围的flush TLB cache entry就行了。
4.3.2 Influencing TLB Performance
使用大页:
- 页尺寸越大,则页表需要存储的条目就越少,则需要做的虚拟地址->物理地址翻译工作就越少,则需要TLB的条目就越少。有些x86/x86-64支持4kB、2MB、4MB的页尺寸。
- 不过大页存在问题,给大页使用的内存区域必须是连续的。
- 如果物理内存的管理基本单位和虚拟内存页一样大的话,浪费的内存就会变多(因为内存申请是以页为单位的,不管你用多少,都会占用1页)。
- 2MB的页对于x86-64系统来说也还是太大了,如果要实现则必须用几个小页组成大页来实现。如果小页是4kB,那么就意味着要在物理内存中连续地分配512个小页。要做到这个比较困难,而且系统运行一段时间物理内存就会变得碎片化。
- Linux系统在操作系统启动时遇险分配了一块内存区域存放大页(
hugetlbs文件系统),固定数量的物理页被保留给虚拟大页使用。 - 所以大页适合在以下场景:性能优先、资源充足、不怕配置繁琐,比如数据库应用。
提高虚拟页最小尺寸(前面讲的大页是可选的)也会产生问题:
- 内存影射操作(比如加载应用程序)必须能够适配页尺寸。比页尺寸更小的映射是不允许的。
- 一个可执行程序的各个部分,在大多数架构中,的关系是固定的。
- 如果页尺寸变得太大,以至于超出了可执行程序所适配的大小,那么就无法加载了。看下图:
|
|
Figure 4.3: ELF Program Header Indicating Alignment Requirements
这是一个x86-64可执行二进制的头,里面规定了内存对齐单位是0x200000 = 2,097,152 = 2MB,如果页尺寸比这个大就不行了。
另一个使用大页的影响是减少page table tree的层级,因为offset变大了,那么剩下的留给页表的部分就变少了,那么page tree walking就更快了,那么TLB missing所要产生的工作就变少了。
下面这段没有看懂:
Beyond using large page sizes, it is possible to reduce the number of TLB entries needed by moving data which is used at the same time to fewer pages. This is similar to some optimizations for cache use we talked about above. Only now the alignment required is large. Given that the number of TLB entries is quite small this can be an important optimization.
4.4 Impact Of Virtualization
大致意思是现代虚拟化技术能够消解大部分因虚拟化导致的TLB性能损失,但是这个开销不会完全消失。
评论