原文:What every programmer should know about memory, Part 2: CPU caches
关键词:Cache prefetching、TLB cache missing、MESI protocol、Cache types(L1d、L1i、L2、L3)
3.1 CPU Caches in the Big Picture
内存很慢,这就是为何CPU cache存在的原因,CPU cache内置在CPU内部,SRAM。 CPU cache尺寸不大。
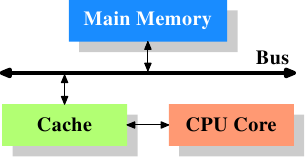
CPU cache处于CPU和内存之间,默认情况下CPU所读写的数据都存在cache中。
Intel将CPU cache分为data cache和code cache,这样会有性能提升。
随着CPU cache和内存的速度差异增大,在两者之间增加了更大但是更慢的CPU cache,为何不扩大原CPU cache的尺寸?答案是不经济。
现代CPU core拥有三级缓存。
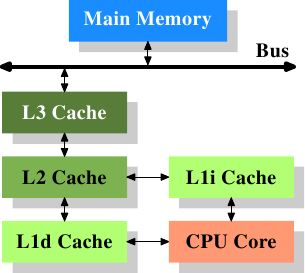
L1d是data cache,L1i是instruction cache(code cache)。上图只是概要,现实中从CPU core到内存的数据流一路上可以通过、也可以不通过各个高层cache,这取决于CPU的设计者,这部分对于程序员是不可见的。
每个处理器拥有多个core,每个core几乎拥有所有硬件资源的copy,每个core可以独立运行,除非它们用到了相同的资源。 每个core有用多个thread,每个thread共享其所属处理器的所有资源,Intel的thread仅对reigster做分离,甚至这个也是有限制的,有些register依然是共享的。
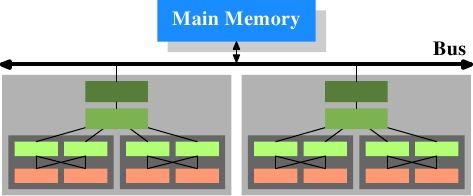
上面这张图:
- 两个处理器,processors,大的灰色矩形
- 每个处理器有一个L3 cache和L2 cache(从上往下看第一个深绿色L3 cache,第二个较浅绿色L2 cache)
- 每个处理器有两个core(小的灰色矩形)
- 每个core有一个L1d cache和L1i cache(两个浅绿色矩形)
- 每个core有两个thread,红色矩形,同一个processor的所有core都共享相同的L2/L3 cache
3.2 Cache Operation at High Level
插播概念word:
Word,数据的自然单位,CPU指令集所能处理的数据单位。在x86-64架构中,word size=64 bits=8 bytes。
CPU cache中存储的条目(entry)不是word,而是cache line,如今一条cache line大小为64 bytes。每次从RAM中抓取数据的时候不仅会将目标数据抓过来,还会将其附近的数据一并抓过来,构成64 bytes大小的cache line。
当一个cache line被修改了,但是还没有被写到内存(main memory),则这个cache line被标记为dirty。一旦被写到内存,则dirty标记被清除。
对于多处理器系统,处理器之间会互相监视写动作,并维持以下规则:
- A dirty cache line is not present in any other processor’s cache.
- Clean copies of the same cache line can reside in arbitrarily many caches.
Cache eviction类型:
- exclusive,当要加载新数据的时候,如果L1d已满,则需要将cache line推到L2,L2转而推到L3,最终推到main memory。优点:加载新数据的时候只需要碰L1d。缺点:eviction发生时代价逐级增高。
- inclusive,L1d中的所有cache line同样存在于L2中。优点:L1d eviction快,因为只需要碰L2。缺点:浪费了一些L2的空间。
下表是Intel奔腾M处理访问不同组件所需的CPU周期:
| To Where | Cycles |
|---|---|
| Register | <= 1 |
| L1d | ~3 |
| L2 | ~14 |
| Main Memory | ~240 |
下图是写不同尺寸数据下的性能表现:
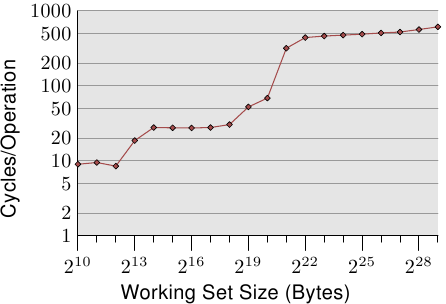
根据经验可以推测出L1d size=2^12=4K,L2 size=2^20=1M。当数据<=4K时,正好能够放进L1d中,操作的CPU周期<10个。当数据>4K and <=1M时,会利用到L2,操作的CPU周期<75。当数据>1M时,CPU操作周期>400,则说明没有L3,此时是直接访问内存了。
非常重要:下面的例子里CPU访问数据是按照以下逻辑:
- CPU只能从L1d cache访问数据
- 如果L1d没有数据,则得先从L2把数据加载到L1d
- 如果L2没有数据,则得先从main memory(RAM)加载数据
也就是说如果这个数据一开始在L1d、L2都不存在,那么就得先从main memory加载到L2,然后从L2加载到L1d,最后CPU才可以访问。
3.3 CPU Cache Implementation Details
3.3.1 Associativity
没看懂。略。
3.3.2 Measurements of Cache Effects
keyword:cache prefetching、TLB cache miss
测试方法是顺序读一个l的数组:
|
|
根据NPAD不同,元素的大小也不同:
- NPAD=0,element size=8 bytes,element间隔 0 bytes
- NAPD=7,element size=64 bytes,element间隔 56 bytes
- NPAD=15,element size=128 bytes,element间隔 120 bytes
- NPAD=31,element size=256 bytes,element间隔 248 bytes
被测CPU L1d cache=16K、L2 cache=1M、cache line=64 bytes。
Single Threaded Sequential Access
case 1: element size=8 bytes
下面是NPAD=0(element size=8 bytes,element间隔0 bytes),read 单个 element的平均时钟周期:
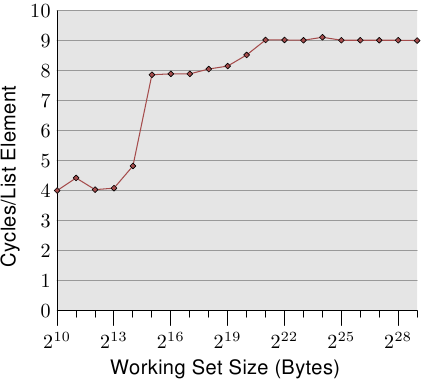
Figure 3.10: Sequential Read Access, NPAD=0
上面的Working set size是指数组的总尺寸(bytes)。
可以看到就算数据尺寸超过了16K(L1d size),对每个元素的读的CPU周期也没有到达14,甚至当数据尺寸超过1M(L2 size)时也是这样,这就是因为cache prefetching的功劳:
- 当你在读L1d cache line的时候,处理器预先从L2 cache抓取到L1d cache,当你读L1d next cache line的时候这条cache line已经准备好了。
- 而L2也会做prefetching动作
Cache prefetching是一项重要的优化手段,在使用连续的内存区域的时候,处理器会将后续数据预先加载到cache line中,也就是说当在访问当前cache line的时候,下一个cache line的数据已经在半路上了。
Prefetching发生既会发生在L1中也会发生在L2中。
case 2: element size >= cache line, 总尺寸 <= L2
各个尺寸element的情况:
- NPAD=7(element size=64 bytes,element间隔56 bytes)
- NPAD=15,element size=128 bytes,element间隔 120 bytes
- NPAD=31,element size=256 bytes,element间隔 248 bytes
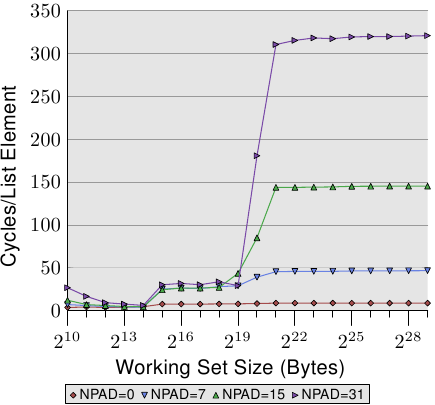
Figure 3.11: Sequential Read for Several Sizes
观察working set size <= L2,看(210~219区段):
- 当working set size <= L1d的时候,时钟周期和NPAD=0持平。
- 当working set size > L1d <= L2的时候,时钟周期和L2本身的周期吻合,在28左右
这是为什么呢?此时prefetching没有起到作用了吗?这是因为:
- prefetching本身需要时钟周期
- 顺序read array实际上就是在顺序read cache line
- 当NPAD=0时,element size=8,就意味着你要read多次才会用光cache line,那么prefetching可以穿插在read之间进行,将next cache line准备好
- 当NPAD=7,15,31时,element size>=cache line,那么就意味着每次read都把一条cache line用完,没有留给prefetching的时钟周期了,下一次read的时候就只能老实从L2加载,所以时钟周期在28左右。
case 3: selement size >= cache line, 总尺寸 > L2
还是看各个尺寸element的情况:
- NPAD=7(element size=64 bytes,element间隔56 bytes)
- NPAD=15,element size=128 bytes,element间隔 120 bytes
- NPAD=31,element size=256 bytes,element间隔 248 bytes
Figure 3.11: Sequential Read for Several Sizes
观察working set size > L2,看(219之后的区段):
- NPAD=7(element size=64),依然有prefetching的迹象
- NPAD=15(element size=128)、NPAD=31(element size=256)则没有prefetching的迹象
这是因为处理器从size of the strides判断NPAD=15和31,小于prefetching window(具体后面会讲),因此没有启用prefetching。而元素大小妨碍prefetching的硬件上的原因是:prefetching无法跨过page boundaries。
而NPAD=15与31的差别很大则是因为TLB cache miss。
测量TLB效果
TLB是用来存放virtual memory address到physical memory address的计算结果的(虚拟内存地址和物理内存地址在后面会讲)。
测试NPAD=7(element size=64),每个元素按照下列两种方式排列的性能表现:
- On cache line,数组中的每个元素连续。也就是每次迭代需要新的cache line,每64个元素需要一个新page。
- On page,数组中的每个元素在独立的Page中。每次迭代需要新的cache line。
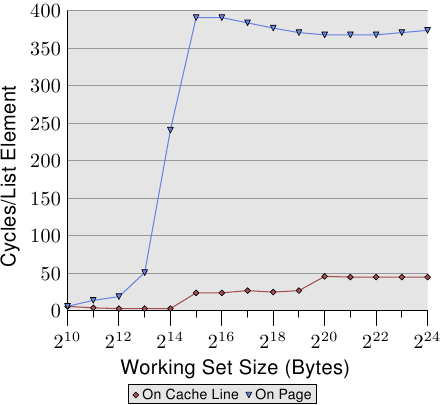
Figure 3.12: TLB Influence for Sequential Read
- 蓝色曲线看到,当数据量超过212 bytes(4K),曲线开始飙升。因此可以推测TLB的大小为4K。
- 因为每个元素大小为64 bytes,因此可以推测TLB的entry数目为64.
- 从虚拟内存地址计算物理内存地址,并将结果放到TLB cache中是很耗时的。
- main memory读取或从L2读取数据到cache line之前,必须先计算物理内存地址。
- 可以看到越大的NPAD就越会降低TLB cache的效率。换句话说,越大的元素尺寸就越会降低TLB cache的效率。
- 所以address translation(地址翻译)的惩罚会叠加到内存访问上,所以Figure 3.11的NPAD=31(element size=256)周期数会比其他更高,而且也比理论上访问RAM的周期高。
case 4: Sequential Read and Write, NPAD=1
测试NPAD=1,element size=16 bytes,顺序读与写:
- Follow,和之前一样是顺序读的测试结果,作为baseline
- Inc,每次迭代对pad[0]++
- Addnext0,每次迭代读取下一个元素的pad[0],把值加到自己的pad[0]上
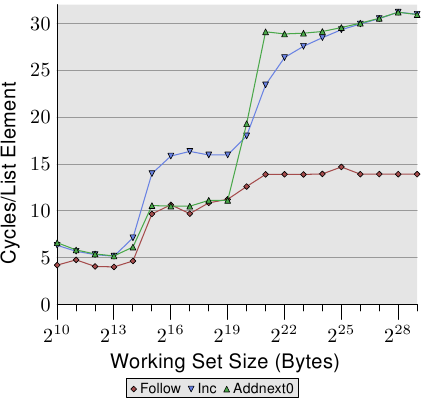
Figure 3.13: Sequential Read and Write, NPAD=1
按照常理来说,Addnext0应该比较慢因为它做的工组比较多,然而在某些working set size下反而比Inc要好,这是因为:
- Addnext0的读取下一个元素的pad[0]这个动作实际上是force prefetch。当程序读取下一个元素的pad[0]的时候,数据已经存在于cache line之中了。
- 所以只要working set size符合能够放到L2中,Addnext0的表现和Follow一样好
下面这段没看懂,也许这不重要。
The “Addnext0” test runs out of L2 faster than the “Inc” test, though. It needs more data loaded from main memory. This is why the “Addnext0” test reaches the 28 cycles level for a working set size of 221 bytes. The 28 cycles level is twice as high as the 14 cycles level the “Follow” test reaches. This is easy to explain, too. Since the other two tests modify memory an L2 cache eviction to make room for new cache lines cannot simply discard the data. Instead it has to be written to memory. This means the available bandwidth on the FSB is cut in half, hence doubling the time it takes to transfer the data from main memory to L2.
case 4: Sequential Read on larger L2/L3
测试NPAD=15,element size=128 bytes。
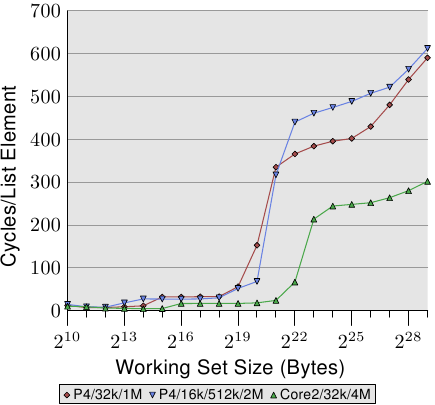
Figure 3.14: Advantage of Larger L2/L3 Caches
- 最后一级cache越大,则曲线逗留于L2访问开销对应的低等级的时间越长
- 第二个处理器在220时比第一个处理快一倍,是因为它的L3
- 第三个处理器表现的更好则是因为它的4M L2
所以缓存越大越能得到性能上的提升。
Single Threaded Random Access Measurements
之前已经看到处理器通过prefetching cache line到L2和L1d的方法,可以隐藏main memory的访问开销,甚至L2的访问开销。但是,只有在内存访问可预测的情况下,这才能工作良好。
下图是顺序访问和随机访问的对比:
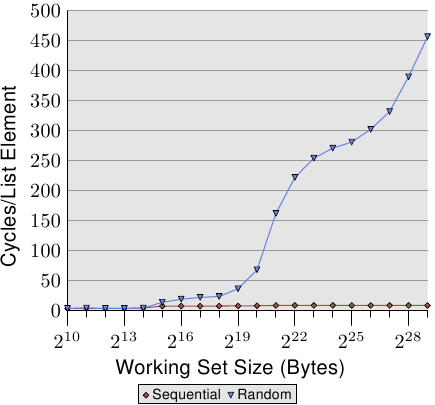
Figure 3.15: Sequential vs Random Read, NPAD=0
后面的没有看懂。
3.3.3 Write behavior
cache应该是coherent的,cache的coherency对于userlevel 代码应该是完全透明的,内核代码除外。
如果一个cache line被修改了,那么自此时间点之后的系统的结果和压根没有cache并且main memory被修改的结果是一样。有两个实现策略:
Write-through:
- 一旦cache line被写,则马上将cache line写到main memory
- 总是保证main memory和cache保持一致,无论什么时候cache line被替换,所cache的内容可以随时丢弃
- 优点:实现起来最简单
- 缺点:虽然简单但是不快。如果一个程序不停的修改一个本地变量,会占用FSB带宽。
Write-back:
- cache line被写不马上写到main memory,仅标记为dirty。
- 当cache line在之后的某个时间点被drop,dirty标记会指导处理器把内容写到main memory
- 绝大多数系统采用的是这个策略
- 处理器甚至可以在驱散cache line之前,利用FSB的空闲空间存储cache line的内容。这样一来就允许清除dirty标记,当需要新空间的时候,处理器就能够直接丢弃cache line。
还有另外两个策略,它们都用于地址空间的特殊区域,这些区域不由实际的RAM支持。
Write-combining:
- Write-combining是一种首先的cache优化策略,更多的用于设备的RAM上,比如显卡。
- 传输数据到设备的开销比访问本地RAM要大得多,所以要尽可能避免传输次数太多。
- 如果仅因为cache line的一个word的修改而要把整个cache line都传输太浪费。
- 因此,write-combining把多个写访问合并在一起,然后再把cache line写出去。
- 这可以加速访问设备RAM的速度。
个人插播:
这个策略牺牲了一定的latency,但是提高了throughput,类似于批处理。
Uncacheable:
- 内存地址压根就不存在RAM里,这些地址一般都是硬编码的。
- 在商业机器上,一般来说这些地址会被翻译成访问card和连接到某个总线的设备(PCIe)。
- 这些内存不应该被缓存。
3.3.4 Multi-processor support
在多处理器系统和多核处理器中,对于所有不共享的cache,都会存在cache内容不一致的问题。两个处理器之间不会共享L1d、L1i、L2、L3,同一处理器的两个核之间至少不会共享L1d。
提供一条能从A处理器直接访问B处理器的cache的通道是不切实际的,因为速度不够快。所以比较实际的做法是将cache内容传输到其他处理器以备不时之需。对于多核处理器也采用这种做法。
那什么时候传输呢?当一个处理器需要一条cache line做读/写,但是它在其他处理器里是dirty时。
那么一个处理器是如何决定一条cache line在另外一个处理器里是否dirty呢?通常来说内存访问是读,而读不会把一个cache line变成dirty。处理器每次对cache line的写访问之后都把cache line信息广播出去是不切实际的。
MESI cache coherency protocol
开发了MESI缓存协同协议(MESI cache coherency protocol),规定了一条cache line的状态有四种:Modified、Exclusive、Shared、Invalid。
- Modified: 本地处理器刚修改cache line,也意味着它是所有cache中的唯一copy。
- Exclusive: cache line没有被修改,但已知没有被加载到任何其他处理的cache中。
- Shared: cache line没有被修改,可能存在于其他处理器的cache中。
- Invalid: cache line无效,比如还未被使用。
MESI所解决的问题和分布式缓存中数据同步的问题是一致的,好好看看,这能够带来一些启发
使用这四个状态有可能有效率地实现write-back策略,同时支持多处理器并发使用read-only数据。
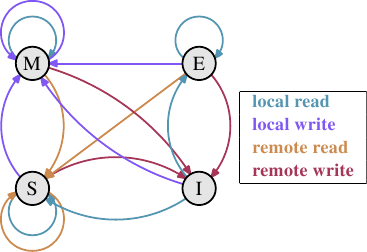
Figure 3.18: MESI Protocol Transitions
下面是四种状态变化的解读:
Invalid:
- 最开始所有的cache line都是空的,也即Invalid
- 如果数据加载到cache line的目的是为了写,变成Modified
- 如果数据加载到cache line的目的是为了读,
- 若其他处理器是否也加载了相同的cache line,变成Shared
- 如果没有,变成Exclusive
Modified
- 如果一条Modified cache line被本地处理器读or写,状态不变。
- 如果B处理器要读A处理器的Modified cache line,则A处理器必须将内容发送给B处理器,然后状态变成Shared。
- 发送给B处理器的数据同样也被memory controller接收和处理,然后存到main memory里。
- 如果这一步没有做,那么状态就不能变成Shared。
- 如果B处理器要写A处理器的Modified cache line,则A处理器要把数据传给B,然后标记为Invalid。
- 这就是臭名昭著的Request For Ownership(RFO)(通过address bus)。在最后一级缓存执行这个操作和I->M一样,代价相对来说是比较高的
- 对于write-through cache,则必须加上在高一级cache写新的cache line,或者写到main memory的时间,进一步增加了代价
Shared
- 如果本地处理器读一条Shared cache line,状态不变。
- 如果本地写一条Shared cache line,则变成Modified。
- 所有其他处理器的cache line copy变成Invalid。
- 所以写操作必须通过RFO广播到其他处理器。
- 如果B处理器要读A处理器的Shared cache line,状态不变。
- 如果B处理器要写A处理器的Shared cache line,则变成Invalid,不牵涉到bus operation。
Exclusive
- Exlusive和Shared一样除了一个区别:本地写不需要RFO。
- 所以处理器会尽可能把多的cache line维持在Exclusive状态,而不是Shared状态。
- 当信息不足的时候,Shared状态作为一种fallback——原文没有说明白是什么信息,猜测应该是当无法知道其他处理器是否拥有相同cache line的时候,就把它设为Shared,这样做会比较安全。
- E->M 比 S->M 快得多
所以在多处理器系统中,除了填充cache line之外,我们还得关注RFO消息对性能的影响。只要出现了RFO消息,就会变慢。
有两种场景RFO消息是必须的:
- 一个线程从一个处理器迁移到另一个处理器,所有的cache line都必须一次性移动到新处理器
- 同一条cache line是真的被两个处理器需要。
- 在稍小一点的尺度上,多核处理器内部就存在这样的情况,只是代价小一点而已,RFO可能会被发送很多次。
影响Coherency protocol速度的因素:
-
RFO出现的频率,应该越低越好
-
一次MESI状态变化必须等所有处理器都应答之后才能成功,所以最长的可能应答时间决定了coherency protocol的速度。
-
FSB是共享资源,大多数系统所有处理器通过同一条bus连到memory controller。如果一个处理器饱和了FSB,则共享同一bus的两个或四个处理器将进一步限制每个处理器可用的带宽。
-
就算每个处理器有自己的bus连接memory controller(Figure 2.2),那么处理器到memory module的bus还是会被共享的。
-
在多线程/多进程程序里,总有一些synchronization的需求,这些synchronization则是使用memory实现的,所以就会有一些RFO消息。
-
所以concurrency严重地受限于可供synchronization的有限带宽。
-
程序应该最小化从不同处理器、不同核访问同一块内存区域的操作。
Multi Threaded Measurements
用之前相同的程序测试多线程的表现,采用用例中最快的线程的数据。所有的处理器共享同一个bus到memory controller,并且只有一条到memory modules的bus。
case 1: Sequential Read Access, Multiple Threads
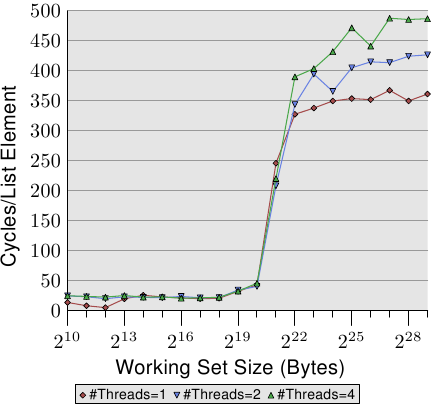
Figure 3.19: Sequential Read Access, Multiple Threads
这个测试里没有修改数据,所有cache line都是shared,没有发生RFO。但是即便如此2线程的时候有18%的性能损失,在4线程的时候则是34%。那么可能的原因就只可能是一个或两个瓶颈所造成的:处理器到memory controller的bus、memory controller到memory modules的bus。一旦working set超过L3尺寸之后,就要从main memory prefetch数据了,带宽就不够用了
case 2: Sequential Increment, Multiple Threads
这个测试用的是 “Sequential Read and Write, NPAD=1,Inc”,会修改内存。
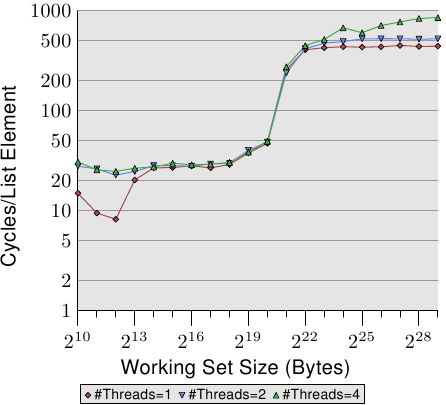
Figure 3.20: Sequential Increment, Multiple Threads
注意图中的Y轴不是线性增加的,所以看上去很小的差异实际上差别很大。
2线程依然有18%的性能损失,而4线程则有93%的性能损失,这意味4线程的时候prefetch流量核write-back流量饱和了bus。
图中也可以发现只要有多个线程,L1d基本上就很低效了。
L2倒不像L1d,似乎没有什么影响。这个测试修改了内存,我们预期会有很多RFO消息,但是并没有看见2、4线程相比单线程有什么性能损失。这是因为测试程序的关系。
case 3: Random Addnextlast, Multiple Threads
下面这张图主要是为了展现令人吃惊的高数字,在极端情况下处理list中的单个元素居然要花费1500个周期。
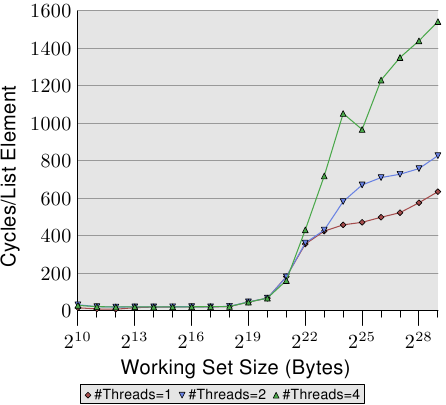
Figure 3.21: Random Addnextlast, Multiple Threads
总结case 1、2、3
把case 1、2、3中的最大working set size的值总结出多线程效率:
| #Threads | Seq Read | Seq Inc | Rand Add |
|---|---|---|---|
| 2 | 1.69 | 1.69 | 1.54 |
| 4 | 2.98 | 2.07 | 1.65 |
Table 3.3: Efficiency for Multiple Threads
这个表显示了在最大working set size,使用多线程能获得的可能的最好的加速。理论上2线程应该加速2,4线程应该加速4。好好观察这个表里的数字和理论值的差异。
下面这张图显示了Rand Add测试,在不同working set size下,多线程的加速效果:
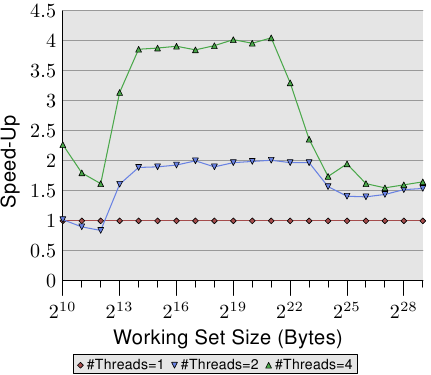
Figure 3.22: Speed-Up Through Parallelism
L1d尺寸的测试结果,在L2和L3范围内,加速效果基本上是线性的,一旦当尺寸超过L3时,数字开始下坠,并且2线程和4线程的数字下坠到同一点上。这也就是为什么很难看到大于4个处理器的系统使用同一个memory controller,这些系统必须采用不同的构造。
不同情况下上图的数字是不一样的,这个取决于程序到底是怎么写的。在某些情况下,就算working set size能套进最后一级cache,也无法获得线性加速。但是另一方面依然有可能在大于两个线程、更大working set size的情况下获得线性加速。这个需要程序员做一些考量,后面会讲。
special case: hyper-threads
Hyper-Threads(有时候也被称为Symmetric Multi-Threading, SMT),是CPU实现的一项技术,同时也是一个特殊情况,因为各个线程并不能够真正的同时运行。超线程共享了CPU的所有资源除了register。各个core和CPU依然是并行运行的,但是hyper-threads不是。CPU负责hyper-threads的分时复用(time-multiplexing),当当前运行的hyper-thread发生延迟的时候,就调度令一个hyper-thread运行,而发生延迟的原因大部分都是因内存访问导致的。
当程序的运行2线程在一个hyper-thread核的时候,只有在以下情况才会比单线程更有效率:2个线程的运行时间之和低于单线程版本的运行时间。这是因为当一个线程在等待内存的时候可以安排另一个线程工作,而原本这个是串形的。
一个程序的运行时间大致可以用下面这个简单模型+单级cache来计算:
Texe = N[(1-Fmem)Tproc + Fmem(GhitTcache + (1-Ghit)Tmiss)]
- N = Number of instructions. 指令数
- Fmem = Fraction of N that access memory. N的几分之几访问内存
- Ghit = Fraction of loads that hit the cache. 加载次数的几分之几命中cache
- Tproc = Number of cycles per instruction. 每条指令的周期数
- Tcache = Number of cycles for cache hit. 命中cache的周期数
- Tmiss = Number of cycles for cache miss. 没命中cache的周期数
- Texe = Execution time for program. 程序的执行时间
为了使用两个线程有意义,两个线程中每个线程的执行时间必须至多是单线程代码的一半。如果把单线程和双线程放到等式的两遍,那么唯一的变量就是cache命中率。不使线程执行速度降低50%或更多(降低超过50%就比单线程慢了),然后计算所需的最小cache命中率,得到下面这张图:
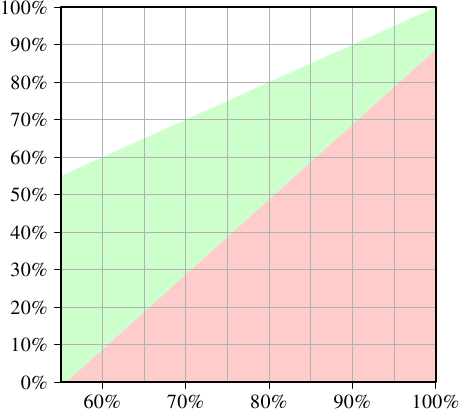
Figure 3.23: Minimum Cache Hit Rate For Speed-Up
X轴代表了单线程代码的Ghit,Y代表了双线程代码所需的Ghit,双线程的值永远不能比单线程高,否则的话就意味着单线程可以用同样的方法改进代码了。单线程Ghit < 55%的时候,程序总是能够从多线程得到好处。
绿色代表的是目标区域,如果一个线程的降速低于50%且每个线程的工作量减半,那么运行时间是有可能低于单线程的运行时间的。看上图,单线程Ghit=60%时,如果要得到好处,双线程程序必须在10%以上。如果单线程Ghit=95%,多线程则必须在80%以上,这就难了。特别地,这个问题是关于hyper-threads本身的,实际上给每个hyper-thread的cache尺寸是减半的(L1d、L2、L3都是)。两个hyper-thread使用相同的cache来加载数据。如果两个线程的工作集不重叠,那么原95%也可能减半,那么就远低于要求的80%。
所以Hyper-threads只在有限范围的场景下有用。单线程下的cache命中率必须足够低,而且就算减半cache大小新的cache命中率在等式中依然能够达到目标。也只有这样使用Hyper-thread才有意义。在实践中是否能够更快取决于处理器是否能够充分交叠一个线程的等待和另一个线程的执行。而代码为了并行处理所引入的其他开销也是要考虑进去的。
所以很明白的就是,如果两个hyper-threads运行的是两个完全不同的代码,那么肯定不会带来什么好处的,除非cache足够大到能够抵消因cache减半导致的cache miss率的提高。除非操作系统的工作负载由一堆在设计上真正能够从hyper-thread获益的进程组成,可能还是在BIOS里关掉hyper-thread比较好。
3.3.5 Other Details
现代处理器提供给进程的虚拟地址空间(virtual address space),也就是说有两种地址:虚拟的和物理的。
虚拟地址不是唯一的:
- 一个虚拟地址在不同时间可以指向不同的物理地址。
- 不同进程的相同的地址也可能指向不同的物理地址。
处理器使用虚拟地址,虚拟地址必须在Memory Management Unit(MMU)的帮助下才能翻译成物理地址。不过这个步骤是很耗时的(注:前面提到的TLB cache缓存的是虚拟->物理地址的翻译结果)。
现代处理器被设计成为L1d、L1i使用虚拟地址,更高层的cache则使用物理地址。
通常来说不必关心cache地址处理的细节,因为这些是不能改变的。
Overflowing the cache capacity是一件坏事情;如果大多数使用的cache line都属于同一个set,则所有缓存都会提前遇到问题。第二个问题可以通过virtual address来解决,但是无法避免user-level进程使用物理地址来缓存。唯一需要记住的事情是,要尽一切可能,不要在同一个进程里把相同的物理地址位置映射到两个或更多虚拟地址。
Cache replacement策略,目前使用的是LRU策略。关于cache replacement程序员没有什么事情可做。程序员能做的事情是:
- 完全使用逻辑内存页(logical memory pages)
- 使用尽可能大的页面大小来尽可能多样化物理地址
3.4 Instruction Cache
指令cache比数据cache问题更少,原因是:
- 被执行的代码量取决于所需代码的大小,而代码大小通常取决于问题复杂度,而问题复杂度是固定的。
- 程序的指令是由编译器生成的,编译器知道怎么生成好代码。
- 程序流程比数据访问内存更容易预测,现代处理器非常擅长预测模式,这有助于prefetching
- 代码总是具有良好的空间、时间局部性。
CPU核心和cache(甚至第一级cache)的速度差异在增加。CPU已被流水线化,所谓流水线指一条指令的执行是分阶段的。首先指令被解码,参数被准备,最后被执行。有时候这个pipeline会很长,长pipeline就意味着如果pipeline停止(比如一条指令的执行被中断了),那它得花一些时间才能重新找回速度。pipeline停止总是会发生的,比如无法正确预测下一条指令,或者花太长时间加载下一条指令(比如从内存里加载)。
现代CPU设计师花费了大量时间和芯片资产在分支预测上,为了尽可能不频繁的发生pipeline停止。
3.4.1 Self Modifying Code
早些时候为了降低内存使用(内存那个时候很贵),人们使用一种叫做Self Modifing Code(SMC)的技术来减少程序数据的尺寸。
不过现在应该避免SMC,因为如果处理器加载一条指令到流水线中,而这条指令在却又被修改了,那么整个工作就要从头来过。
所以现在到处理器假设code pages是不可变的,所以L1i没有使用MESI,而是使用更简单的SI
3.5 Cache Miss Factors
我们已经看到内存访问cache miss导致的开销极具增大,但是有时候这个问题是无法避免的,所以理解实际的开销以及如何缓解这个问题是很重要的。
3.5.1 Cache and Memory Bandwidth
测试程序使用x86和x86-64处理器的SSE指令每次加载16 bytes,working set size从1K到512M,测试的是每个周期能够加载/存储多少个bytes。
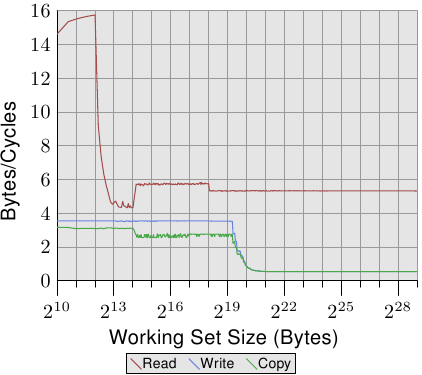
Figure 3.24: Pentium 4 Bandwidth
这个图是64-bit Intel Netburst处理器的测试结果。
先看读的测试可以看到:
- 当working set size在L1d以内的时候,16 bytes/cycle
- 当L1d不够用的时候,性能下降很快,6 bytes/cycle
- 到218的时候又下降了一小段是因为DTLB耗尽了,意思是对每个新page需要额外工作。
- 这个测试是顺序读的,很利于prefetching,而在任何working set size下都能够达到5.3/cycle,记住这些数字,它们是上限,因为真实程序永远无法达到这个值。
在看写和copy的测试:
- 就算是最小的working set size,也不超过4 bytes/cycle。这说明Netburst处理器使用的Write-through策略,L1d的速度显然受制于L2的速度。
- copy测试是把一块内存区域copy到另一个不重叠的内存区域,因为上述原因它的结果也没有显著变差。
- 当L2不够用的时候,下降到0.5 bytes/cycle。
下面是两个线程分别钉在同一核心的两个Hyper-thread上的测试情况:
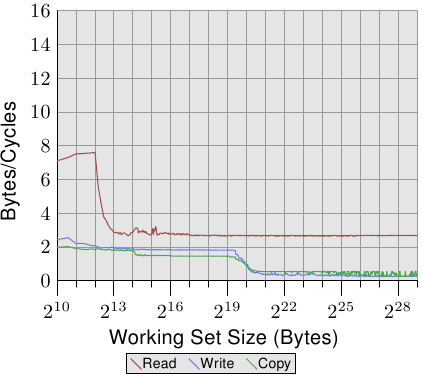
Figure 3.25: P4 Bandwidth with 2 Hyper-Threads
这个结果符合预期,因为Hyper-thread除了不共享register之外,其他资源都是共享的,cache和带宽都被减半了。这意味着就算一个线程在在等待内存的时候可以让另一个线程执行,但是另一个线程实际上也在等待,所以并没有什么区别。
下图是Intel Core2处理器的测试结果(对比Figure 3.24):
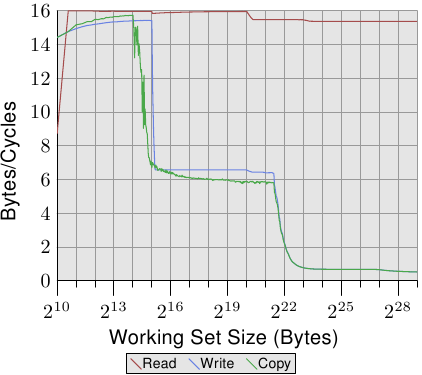
Figure 3.26: Core 2 Bandwidth
Core 2 L2是P4 L2的四倍。这延迟了write和copy测试的性能下跌。read测试在所有的working set size里都维持在16 bytes/cycle左右,在220处下跌了一点点是因为DTLB放不下working set。能够有这么好的性能表现不仅意味着处理器能够及时地prefetching和传输数据,也意味着数据是被prefetch到L1d的。
看write和copy的表现,Core 2处理器的L1d cache没有采用Write-through策略,只有当必要的时候L1d才会evict,所以能够获得和read接近的表现。当L1d不够用的时候,性能开始下降。当L2不够用的时候再下跌很多。
下图是Intel Core2处理器双线程跑在两个核心上:
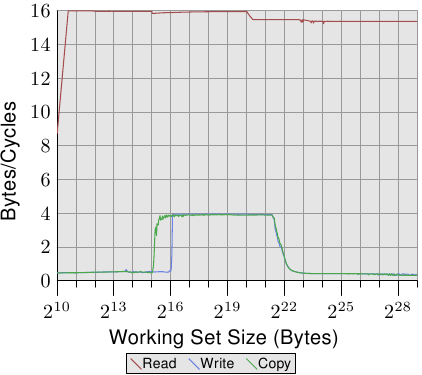
Figure 3.27: Core 2 Bandwidth with 2 Threads
这个测试两个线程分别跑在两个核心上,两个线程访问相同的内存,没有完美地同步。read性能和Figure 3.26没有什么差别。
看write和copy的表现,有意思的是在working set能够放进L1d的表现和直接从main memory读取的表现一样。两个线程访问相同的内存区域,针对cache line的RFO消息肯定会被发出。这里可以看到一个问题,RFO的处理速度没有L2快。当L1d不够用的时候,会将修改的cache line flush到共享的L2,这是性能有显著提升是因为L1d中的数据被flush到L2,那就没有RFO了。而且因为两个核心共享FSB,每个核心只拥有一半的FSB带宽,意味着每个线程的性能大约是单线程的一半。
厂商的不同版本CPU和不同厂商的CPU的表现都是不同的。原文里后面比较了AMD Opteron处理器,这里就不写了。
3.2.5 Critical Word Load
数据是一block为单位从main memory传输到cache line的,一个block大小为64 bits(记得前面说的word也是64 bits),一条cache line的大小是64/128 bytes,所以填满一个cache line要传输8/16次。
后面没有看懂,大致意思是Critical word是cache line中的关键word,程序要读到它之后才能继续运行,但是如果critical word不是cache line的第一个,那么就得等前面的word都加载完了之后才行。blah blah blah,不过这个理解可能也是不对的。
3.5.3 Cache Placement
cache和hyper-thread、core、处理器的关系是程序员无法控制的,但是程序员可以决定线程在哪里执行,所以cache和CPU是如何关联的就显得重要了。
后面没仔细看,大致讲了由于不同的CPU架构,决定如何调度线程是比较复杂的。
3.5.4 FSB Influence
不细讲了,对比了667MHz DDR2和800 MHz DDR2(20%的提升),测试下来性能有18%的提升接近理论值(20%)。
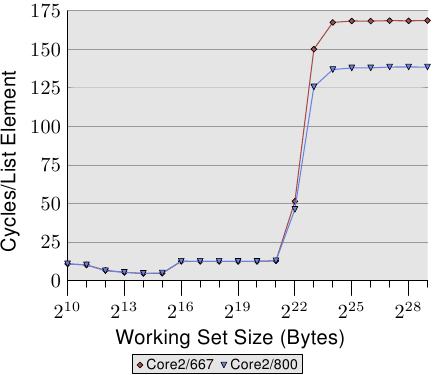
Figure 3.32: Influence of FSB Speed
所以更快的FSB的确能够带来好处。要注意CPU可能支持更高的FSB,但是主板/北桥可能不支持的情况。
评论