Rancher中启动监控后,Prometheus采集到的cpu、memory、network的指标存在重复,见这个issue,该问题在2.3.0~2.4.x中都存在。下面讲解决办法:
先设置Grafana的admin密码,进入System项目,cattle-prometheus命名空间,找到grafana-cluster-monitoring,进入其Shell:
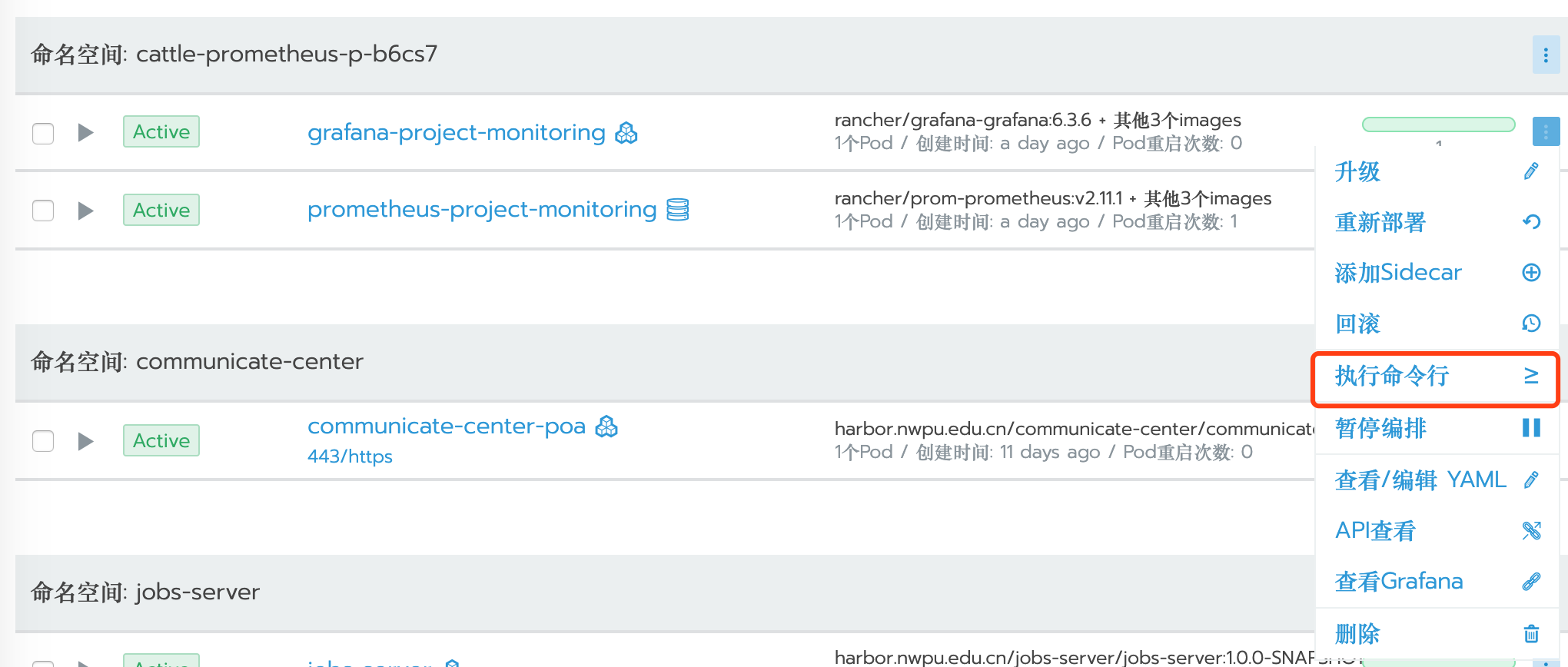
执行:
|
|
然后随便进入一个Deployment/StatefulSets,进入Grafana:

用admin账号和你刚才设置的密码登录进去,进入管理页面导入Dashboard:
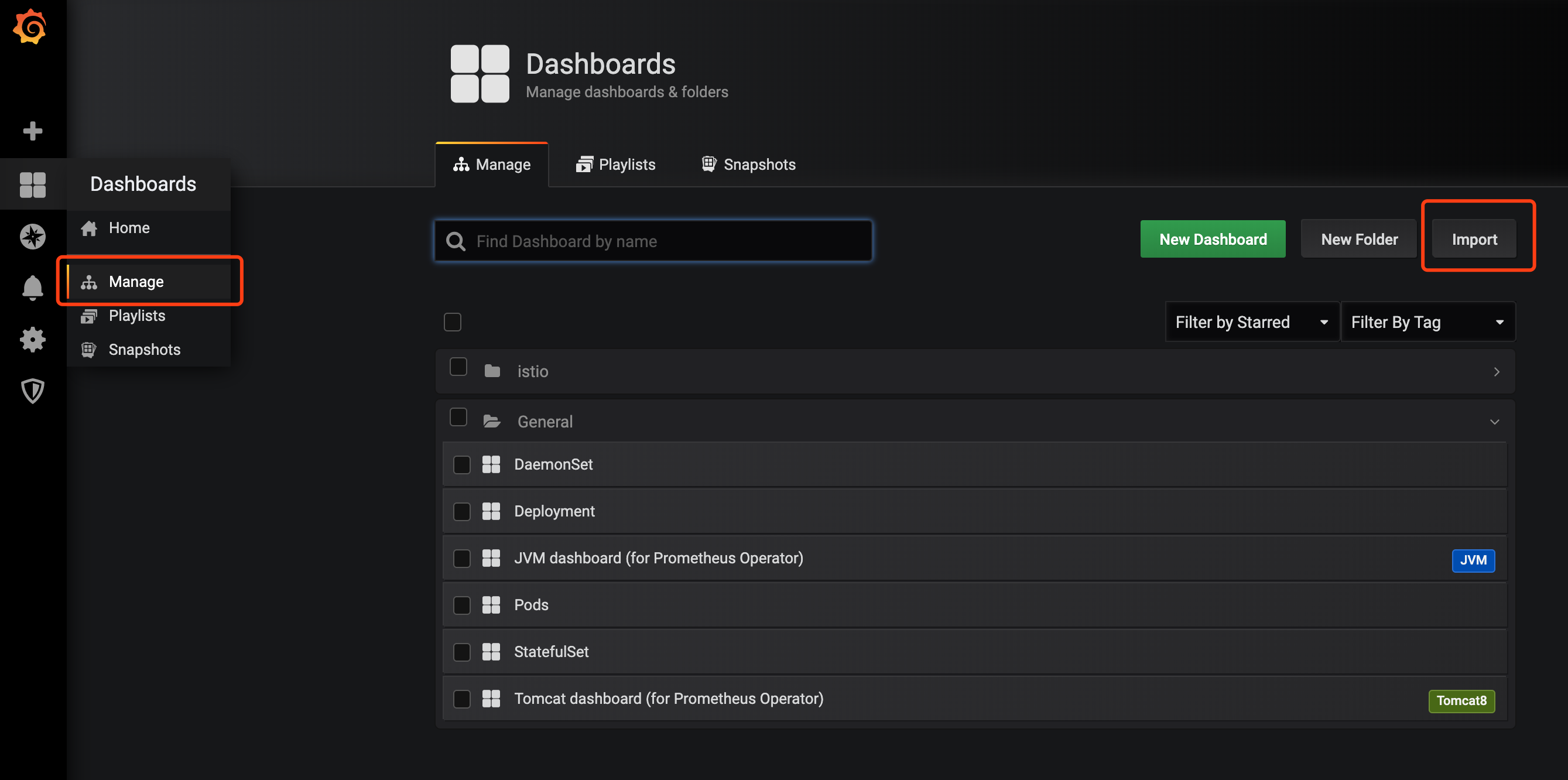
导入修正后的Dashboard:
- ID 13087,Rancher DaemonSet(fixed)
- ID 13088,Rancher Deployment(fixed)
- ID 13089,Rancher Pods(fixed)
- ID 13090,Rancher StatefulSet(fixed)
评论