原文:Scheduling In Go : Part I - OS Scheduler
几个数字
| operation | cost |
|---|---|
| 1纳秒 | 可以执行12条指令 |
| OS上下文切换 | ~1000到~1500 nanosecond,相当于~12k到~18k条指令。 |
| Go程上下文切换 | ~200 nanoseconds,相当于~2.4k instructions条指令。 |
| 访问主内存 | ~100到~300 clock cycles |
| 访问CPU cache | ~3到~40 clock cycles(根据不同的cache类型) |
操作系统线程调度器
你的程序实际上就是一系列需要执行的指令,而这些指令是跑线程里的。
线程可以并发运行:每个线程轮流占用一个core;也可以并行运行:每个线程跑在不同core上。
操作系统线程调度器负责保证充分利用core来执行线程。
程序指令是如何执行的
程序计数器(program counter,PC),有时也称为指令指针(instruction pointer,IP),用来告诉线程下一个要执行的指令(注意不是当前正在执行的指令)的位置。它是一种寄存器(register)。
每次执行指令的时候都会更新PC,因此程序才能够顺序执行。

线程状态
- Waiting:等待中。原因:等待硬件(比如磁盘、网络)、正在系统调用(syscall)、阻塞在同步上(atomic、mutex)
- Runnable:可以运行,正在等待调度。越多线程等待调度,大家就等的越久,且分配到的时间就越少。
- Executing:正在某个core上运行。
任务类型
- CPU绑定:这种任务永远不会让线程进入Waiting状态,比如计算Pi。
- IO绑定:这种任务会让线程进入Waiting状态。
上下文切换
Linux、Mac和Windows使用的是抢占式调度器,所以:
- 你无法预测调度器什么时候会运行哪个线程。线程优先级混合事件(比如接收网络数据),也使得预测调度器行为变得不可能。
- 如果你要有确定的行为,那么就应该对线程做同步和编排(synchronization and orchestration)。否则你观察到现在是这个样子的,无法保证下次还是这个样子的。
在一个core上切换线程的物理行为称为上下文切换(context switching)。调度器把一个线程从core上换下来,然后把另一个线程换上去。换上去的线程状态从Runnable->Executing,换下来的线程的状态从Executing->Runnable(如果依然可以运行),或者Executing->Waiting(因为等待所以被换下来)。
上下文切换的代价比较高,大概在**~1000到~1500 nanosecond之间,考虑到core大致每纳秒可以执行12条指令,那么就相当于浪费了~12k到~18k的指令**。
如果是IO绑定任务,那么上下文切换能够有效利用CPU,因为A线程进入Waiting那么B线程就可以顶上使用CPU。
如果是CPU绑定任务,那么上下文切换会造成性能损失,因为把CPU能力白白浪费在上下文切换上了(浪费了~12k到~18k的指令)。
少即是多
越少的线程带来越少的调度开销,每个线程能分配到的时间就越多,那么就能完成越多的工作。
Cache line
访问主内存(main memory)的数据的延迟大概在**~100到~300 clock cycles**。
访问cache的数据延迟大概在 ~3到~40 clock cycles(根据不同的cache类型)。

CPU会把数据从主内存中copy到cache中,以cache line为单位,每条cache line为64 bytes。所以多线程修改内存会造成性能损失。
多个并行运行的线程访问同一个数据或者相邻的数据,那么它们可能就会访问同一条cache line。任何线程跑在任何core上都有一份自己的cache line copy。所以就有了False Sharing问题:
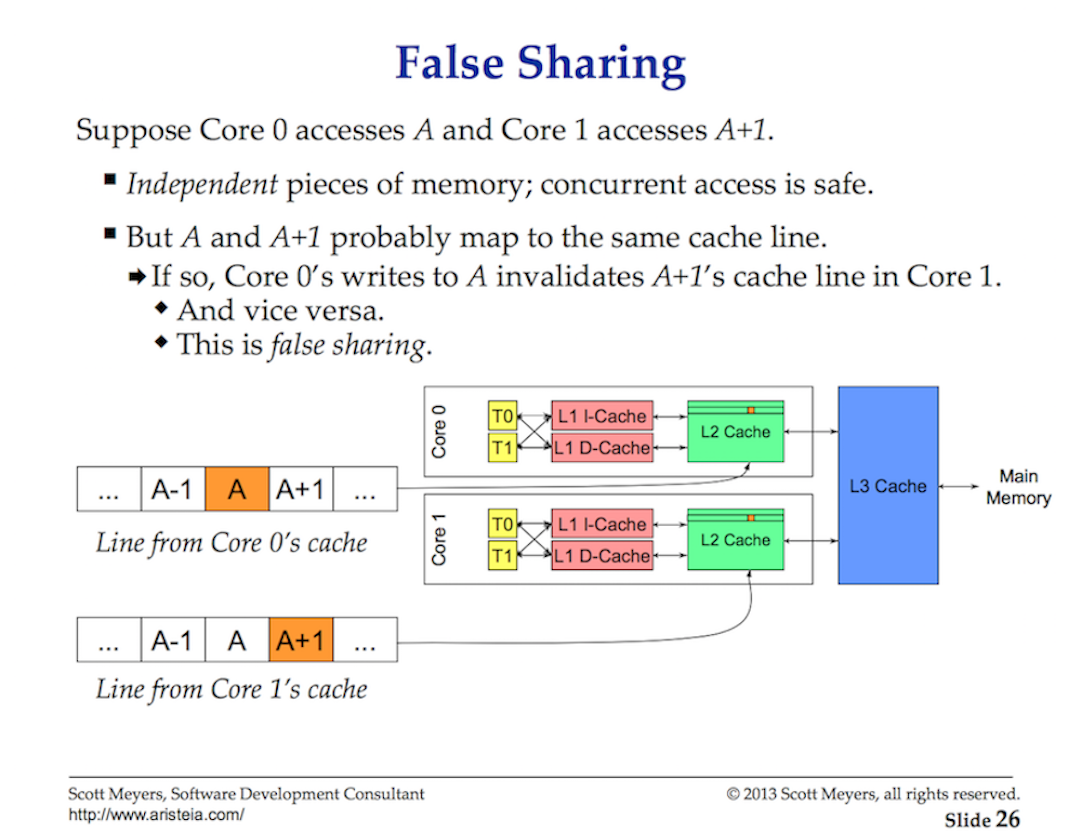
只要一个线程操作了自己core上的某个cache line,那么这个cache line在其他core就会变脏(cache coherency),当一个线程访问一个脏cache line的时候,就要访问一下main memory(~100到~300 clock cycles)。当单处理器core变多的时候,以及当有多个处理器(处理器间通信)的时候,这个开销就变得很大了。
评论