先导概念:
- 读锁:可以并发读,如果有写操作,则必须等读锁释放
- 写锁:不能并发读,也不能并发写,都必须等写锁释放才能继续
锁的类型:
- 全局锁
- 表级锁:表锁、MDL锁
全局锁
使用FLUSH TABLES WITH READ LOCK会让你给整个数据库加一个读锁。这会阻塞所有DML、DDL、更新类事务的commit,直到被释放。
全局锁的典型使用场景是MyISAM引擎做全库逻辑备份,为的是解决备份时数据不一致的问题。
如果是InnoDB引擎的表,因为支持MVCC,可以通过mysqldump --single-transaction来解决备份时数据一致性问题。
释放方法:
|
|
表级锁
表锁
通过下面语句给表加上读锁或写锁,还有释放:
|
|
MySQL的锁不是可重入的,即加锁之后,当前连接/session也受制于这个锁。
如果加的是读锁:
- 本session:可以读,不可写(直接报错)
- 其他session:可以读,阻塞写
如果加的是写锁:
- 本session:可以读、可以写
- 其他session:阻塞读、阻塞写
元数据锁(Metadata Lock,MDL)
访问表的时候会被自动加上(隐式):
- 在CRUD一个表的时候,加上MDL读锁
- 对表结构变更的时候,加上MDL写锁
陷阱:MDL锁在语句开始时申请,但是要在事务提交之后才会释放。所以下面语句会导致很多数据库操作被阻塞:
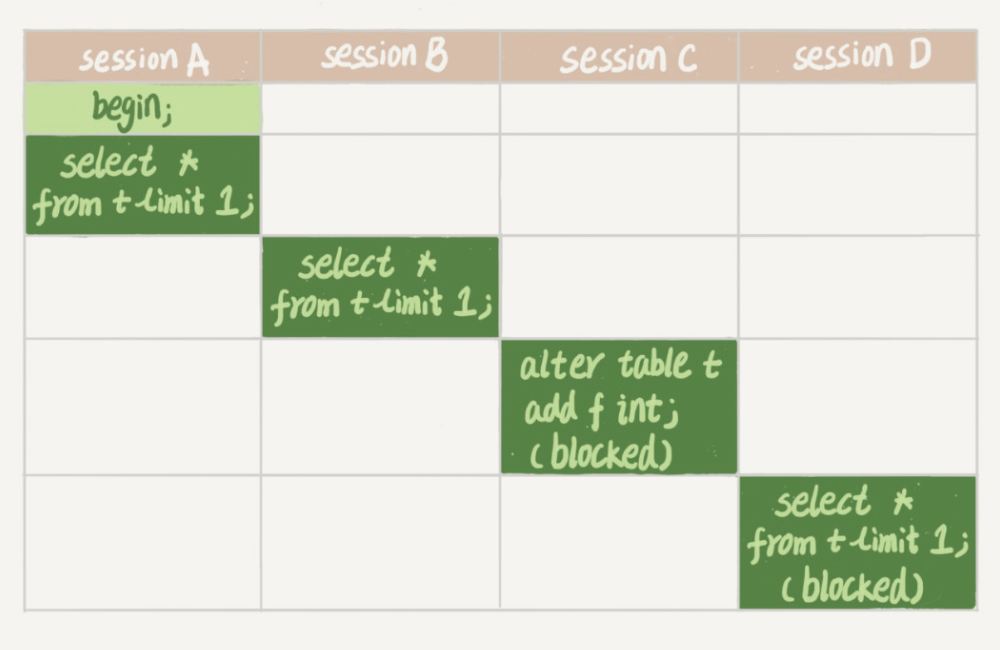
- session A开启事务,查询,得到MDL读锁
- session B查询,得到MDL读锁
- session C加字段,要得到MDL写锁,阻塞
- session D查询,要得到MDL读锁,但是前面有写锁在排队,阻塞
因为session A没有提交事务,所以就造成了后续一连串的阻塞。如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满。
解决办法:
问题的本质在于一个MDL写锁在等待MDL读锁的释放,而读锁却在一个长事务里,导致后续的MDL读锁堆积。
所以可以在执行DDL之前看有没有长事务在跑,如果有,Kill掉这个长事务,或者等待长事务结束再DDL。
还可以给DDL添加超时时间,如果等待超时则放弃,然后人工再重试(MariaDB和AliSQL支持下面语法):
|
|
行锁
InnoDB支持行锁,MyISAM不支持。所以行锁是做在存储引擎上的。
比如下面:
| 事务A | 事务B |
|---|---|
| begin; update t set k=k+1 where id=1; update t set k=k+2 where id=2; |
|
| begin; update t set k=k+2 where id=1; |
|
| commit; |
很容易就能猜到,事务B会被阻塞,直到事务A提交。所以:
- 行锁在需要的时候才获取(执行具体语句时)
- 事务持有的行锁在事务提交时才会被释放。(这个和MDL锁一样一样的)
所以为了降低锁的影响,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放,这样锁持有的时间变短了,降低并发时事务之间产生的等待。
下面两种写法也会加上行锁:
select ... lock in share mode,加上读锁(S锁,共享锁)select ... for share,8.0 新增语法,效果同上select ... for update,语义和UPDATE/DELETE一样,加上写锁(X锁,排他锁)
SELECT ... FOR SHARE/LOCK IN SHARE MODE 只会锁定扫描过程中使用的索引里的记录行,即如果你的查询正好使用了覆盖索引,那么只有这个索引里的记录行会被锁定,主键索引的记录行是不会被锁定的。
SELECT ... FOR UPDATE除了会锁定扫描过程中使用的索引里的记录行,相关的索引的记录行也会被锁定。换句话说如果你使用了覆盖索引,但是主键索引里的记录行也会被锁定。而又因为主键索引就已经包含了所有字段,那么就相当于锁定表的整行记录。
所以一定要注意,MySQL锁定的行实际上是索引上的行,只不过有时候锁定的是主键索引,看上去像锁定整行一样
更多参考资料,详情见SELECT 语法和Locking Reads
死锁
因为上面的两个特性,很容易造成死锁:
| 序号 | 事务A | 事务B |
|---|---|---|
| 1 | begin; | begin; |
| 2 | update t set k=k+1 where id=1; | |
| 3 | update t set k=k+1 where id=2; | |
| 4 | update t set k=k+1 where id=2; | |
| 5 | update t set k=k+1 where id=1; | |
| 6 | commit; | commit; |
其实在4和5的时候,事务A和事务B就都不能继续下去了,大家互相等待。
解决办法:
- 系统参数
innodb_lock_wait_timeout,控制事务等待行锁的超时时间(秒)。默认50秒。 - 系统参数[
innodb_deadlock_detect][7],开启死锁检测。默认on。发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。
死锁检测的过程:每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待,也就是死锁。
死锁检测高并发情况下拖慢速度
假设有 1000 个并发线程要同时更新同一行,每个线程都要检测是否和其他线程形成死锁,那么死锁检测操作就是 100 万这个量级的。于是出现**“CPU 利用率很高,但是每秒却执行不了几个事务“**。
解决办法:
- 保证程序不会出现死锁,然后把死锁检测关掉。不靠谱。
- 控制并发度,最好对同一行的修改串行化。依赖于中间件或者修改MySQL源码。
- 锁的条带化(Java并发编程里的概念),比如影院账号的例子,把账号分成10个,减少锁的冲突。
加锁的顺序
先给哪行加锁,后给哪行加锁,是有讲究的,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。。什么比如一个购票的业务:
- 从顾客 A 账户余额中扣除电影票价;
- 给影院 B 的账户余额增加这张电影票价;
- 记录一条交易日志。
显然更新影院B账户余额的并发度比更新顾客A账户余额高很多,应该把它放后面。可以按照3、1、2的顺序执行。
评论