场景概述:假设你有个N个服务器,你想要把你的数据均匀的分配到这N个服务器中,并且每次取数据的时候到对应的服务器去取。
方案一:轮询+字典表
给数据生成一个key,轮询的方式把数据存到这N个服务器中,并且保存一个key->服务器的字典。
增加服务器时:老服务器总是会比新服务器存更多数据
删除服务器时:需要更新字典,因为某些key对应的服务器已经不存在了
优点:很均匀
缺点:需要维护字典,这个有额外开销。同时这个字典会变成瓶颈。
方案二:hash取模分配
给数据生成一个key,取数据和存数据的时候都用serverIndex = hash(key) mod N得到服务器编号。关于hash函数,得使用结果均匀的算法,Java的hashCode不均匀,有以下选择:
增加服务器时:所有的key都得重新取模
删除服务器时:所有的key都得重新取模
优点:没有保存字典的开销
缺点:增加和删除服务器的时候需要移动所有key
方案三:一致性hash
一致性hash为了解决前一种方案的缺点,提出了一种可以在增加or删除服务器的时候只移动1/N个key的办法。
想象有一个环,上面有232个点,每个服务器在这个环上都有一个点,给定一个key怎么找对应的服务器?先hash(key)得到它所在的点,然后顺时针找到第一个服务器:
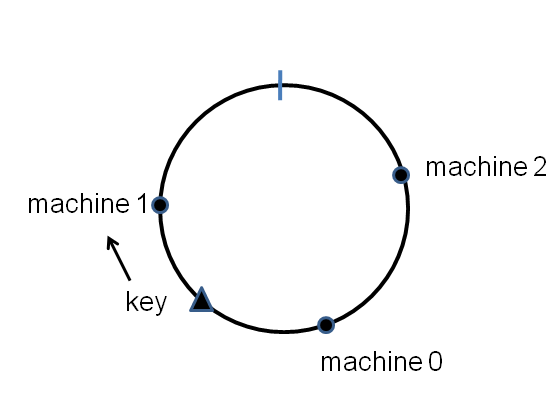
当增加or删除服务器的时候,key沿着顺时针找到下一个服务器就行,如果服务器在环上的分布均匀(即间隔均匀),那么也就只有1/N的会产生移动。
但是随着服务器的增加or删除,总是会不均匀,因此我们可以给服务器增加分身(即虚拟节点):
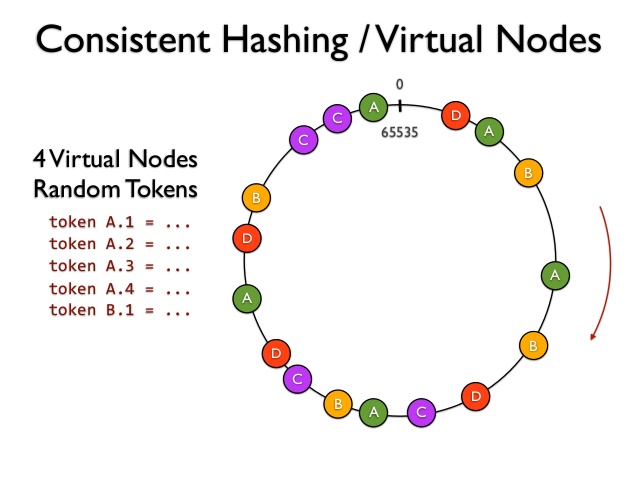
可以看到A、B、C三个服务器在环上的位置不止一个,这样就能解决key分布不均匀的问题。
参考代码
感谢Tom White - Consistent Hashing,他给出了一种Java的参考实现:
|
|
代价
那么每个服务器多少个虚拟节点才能使得分布均匀呢?
Consistent Hashing: Algorithmic Tradeoffs提到:
每个服务器100个虚拟节点,负载的标准差为10%,1000个虚拟节点时负载的标准差为~3.2%。这就意味着具有较大的内存开销
不过我认为你有100台服务器,每个1,000个虚拟节点,Map中放100,000个entry占用的空间也不大。
这篇文章里也提到了更多其他的算法,各有利弊。
参考资料
- Tom White - Consistent Hashing,介绍了基本概念
- Consistent Hashing: Algorithmic Tradeoffs,提到了更多算法实现及利弊
- Distributing Content to Open Connect,提到了服务器本身规格有差别的情况
- Consistent Hashing in Cassandra
评论